








Easy now
We are SNIGEL
Snigel is an independent Swedish company, run by a group of officers, designers and engineers who are passionate about elevating the quality and function of personal equipment for modern soldiers and law enforcement officers. It was founded in 1990 by PH, an Airborne Ranger. He was driven by a personal quest to create the world’s ultimate backpack, combat vest and uniform. Guided by a “no compromises” approach to function, quality and comfort, he later earned an MFA in Industrial Design and started designing early versions of many of the carrying platforms we now offer.
Today, Snigel continues to be powered by passion. We design the products ourselves and use them in the Swedish Army where we are part-time soldiers. Our experience, combined with our customers’ expertise, forms the basis for the improvements that we constantly make to our products. Like you, we are never 100% satisfied, always looking ahead, innovating and pushing the limits of what is possible.
At the end of the day, our mission is to support you with the world’s best carrying systems and protective solutions to keep you safe and performing well. And since no two needs are exactly the same, we encourage you to get in touch and tell us your specific challenges. If we can’t find a solution, maybe we can invent one together. We’d love to hear from you.
OLD BRAND BRAND NEW
HEAD-ON
Here is our new logotype, with the new wordmark.
We have streamlined the original SnigelDesign to SNIGEL.
This is mirroring the fact that even though we are deeply rooted in industrial design, the company has since long moved forward. We are designers, engineers and developers as well as manufacturers, distributors, suppliers, consultants.
The logo is now facing forward in a symmetrical, heraldic manner, easily recognized in small as well as large sizes.
Snigel is Swedish for snail, a creature of the nature always carrying its house on the back. The name symbolizes the backpacks that everything started with, as well as the strong shield protecting the user.
Snails are pretty cool too, if you ask us.


FOR YEARS TO COME
True to our legacy
A Snigel product is not easily worn out. For years to come products with the old SnigelDesign tag will be the backbone of many of our customers equipment. We swear by all products delivered and we guarantee their function whichever logo they carry.
You will also be able to order SnigelDesign branded stock items for a long time still.
We are rebranding to SNIGEL from SnigelDesign.
Our uncompromising quality, solid functionality and forefront technology will still be the same.
Remember where you saw it first?
Innovations
SNIGEL INNOVATIONS
Single-hand pouch zipper (Oyster)
Anyone who’s ever tried opening a pouch attached to the side of a combat vest with one hand knows how frustrating a snagging zipper and floppy pouch top can be. The stiffened Oyster zipper design ensures smooth, snag-free, single-hand operation – every time, in every condition.




SNIGEL INNOVATIONS
Vest weight-transfer system (Spoon)
The Spoon weight-transfer system shifts the bulk of the weight of a ballistic vest or backpack from the shoulders to the hips. The system comprises a flat steel member, the Spoon, an attachment point for the combat belt, the Garage, and an adjustable sleeve for a vest or backpack. The centre back fixture and rounded end of the Spoon provide ergonomically correct pivoting of the belt, allowing your lower body to move as you walk without shifting the load with each step.
The Spoon garage features two compartments that let you comfortably carry a backpack over the combat vest. This also eliminates the need for a separate hip belt on your backpack (the “belt-on-belt” syndrome) since the combat belt is used for both the vest and the backpack. The quick-release function allows for emergency dumping of the pack without removing the vest or belt.
Many of our backpacks and vests are compatible with the Spoon system.






SNIGEL INNOVATIONS
Quick adjust, ballistic vest tightening (Squeeze)
Our Squeeze platform applies the “close first – tighten after” thinking used in our Strap-on vest concept, while giving you a full-on scalable system. The vest platform consists of two sizes of front-and-back modules and three sizes of side panel modules. It provides an accurate and comfortable fit for 95% of the military population, without overloading the logistics supply chain. It is also scalable – from a light-weight plate carrier to full robocop protection – including, neck, shoulders, upper arm, lower arm, groin and thighs.
For details, see the Squeeze Ballistic Vest platform.




SNIGEL INNOVATIONS
Clip-in shotgun holder
Combined with a weapon sling, this belt-mounted Kydex clip keeps a standard pistol-grip shotgun firmly attached to your side while repelling, running or breaching. The springy clip allows for very quick access when the weapon is needed.




SNIGEL INNOVATIONS
Single-hand pull ballistic vest tightening
For the best fit and most comfortable wearing, you want to secure the closing of your ballistic vest first and then tighten the fit to the desired level. This also allows for fine adjustments, depending on how much clothing you’re wearing under the vest. This feature was first developed with a front, single-hand pull tab in the Strap-on vest concept.






SNIGEL INNOVATIONS
Shifted knee pad pockets
When you kneel down from a standing position, your pant legs will twist a little. To ensure that the protective pads actually end up in the correct knee position, we found that the pockets holding them have to be shifted slightly to the side. A small innovation you might think, but a huge help if you’re kneeling a lot.




SNIGEL INNOVATIONS
Adjustable multi-size fragmentation grenade pouch
Modern fragmentation grenades come in various sizes. To avoid having to change the pouches on your vest for each new grenade type, we made one that was easily adjustable.




SNIGEL INNOVATIONS
Ventilated knee and elbow pads
Foam pads have their limits. While ideal for cushioning knees and elbows, they also restrict air circulation and may become uncomfortably hot in warmer climates. To overcome this, we introduced ventilated protection pads and the response has been very positive.

SNIGEL INNOVATIONS
Vest-attached small packs
Many of our smaller backpacks have shoulder straps and hip belts that can either be folded away or detached completely. This allows you to carry the pack, clipped directly to the back of your combat vest. It also eliminates the extra straps going across your gear on the chest and prevents it from slipping off the shoulders of your vest. By unclipping the buckles on one side, the pack also swings forward for easy access to the contents without taking the pack completely off.




SNIGEL INNOVATIONS
Covert backpack
Our covert backpack is ideal for surveillance teams or anyone needing to very discreetly carry a ballistic vest, short-barrel weapon, magazines, radio or more. Whether you carry it on your back or use it as a messenger bag, it’s easy to quickly open and put over the head to provide front and back ballistic plate protection. The weapon is securely attached to the front section, ready for use. The pack comes with separate lid covers that can be attached to change the appearance.





SNIGEL INNOVATIONS
Weapon back attachment
Originally developed for divers to safely carry MP5s on their backs while boarding ships, this back attachment can also be used when climbing, repelling or running. Pull the handle to release the securing pin. The weapon swings forward and comes to rest at your hip where it can easily be grasped and brought to bear.









SNIGEL INNOVATIONS
Single-hand shotgun shell pouch
This handy pouch was originally designed for door breaching when you need quick access to many more shells than the gun’s magazine can hold. The innovative top, with overlaying elastic flaps, keeps loose shells securely inside while allowing the operator to just push his hand through to reload.




SNIGEL INNOVATIONS
With this pouch, you can carry two distraction grenades, readily accessible on your vest, and engage without lowering your primary weapon or taking your eyes off the target. The pouch holds the grenades protected and secure under double flaps in transportation mode. Open and fold back the flaps for ready mode, grab and pull the grenade to disengage the pin, throw. All with one hand.




SNIGEL INNOVATIONS
Modular weapon sling system
A traditional weapon sling tends to put an uncomfortable load on the neck and shoulders, especially after prolonged use. By attaching the weapon with a short sling to the combat vest, this problem is avoided. As an added benefit, the weapon is easily and quickly accessible and the one-point sling doesn’t obstruct magazine changes as most long slings can do. With the Snigel Modular weapon sling, you get both options.



SNIGEL INNOVATIONS
Roll-up dump bag
In a firefight, you need a fast and secure way to store empty magazines. Now, instead of sticking them in your pockets or uniform jacket, you can easily drop them in the dump bag. The bag is carried out of the way, rolled up and attached to the bottom of a combat or equipment vest. When needed, just pull down on the large D-ring and start stuffing through the easy-access opening. The top has a zipped lid and works equally well for carrying gloves, ear defenders and other light gear.






SNIGEL INNOVATIONS
Ergonomic Police equipment belt
The problem with traditional belts is that they don’t provide enough padding or surface area to prevent chafing and discomfort from pressure points. Also, attached pouches or equipment tend to shift or even fall off when the belt is removed. To solve this, we developed the Snigel Police equipment belt. It utilizes a sturdy 50 mm outer belt to carry any standard pouch or piece of gear and a wider, padded inner belt for support and comfort. The inner and outer parts are attached with Velcro along the entire length, ensuring that the belt retains its pre-bent shape and that everything attached stays in place when you take it off.




SNIGEL INNOVATIONS
Silent hook pouch closure mechanism
Let’s face it, buttons and buckles can be fiddly to use with one hand in the dark and Velcro is noisy. To overcome these issues, we developed the “Silent hook” pouch closure mechanism. Secure, silent, hard-wearing single-hand operation using a guided metal hook, elastic and webbing.






SNIGEL INNOVATIONS
Shin pockets
The best place to carry first-aid kits is in designated pockets in front of your shins. Not only do the packs provide bump protection for the lower leg, but the position ensures ready access when kneeling to treat a wounded comrade.



SNIGEL INNOVATIONS
User-facing hip bag top lid (Funny pack)
Traditionally, the zipped top-lids of hip bags are designed with flaps that flip up and inward towards the wearer. But this also obscures the content of the bag. So we simply switched the opening position around. Now, by opening the lid away from the wearer, the inside of the bag remains in full view. What’s more, the underside of the flap can be used to carry small objects that are easily accessible.


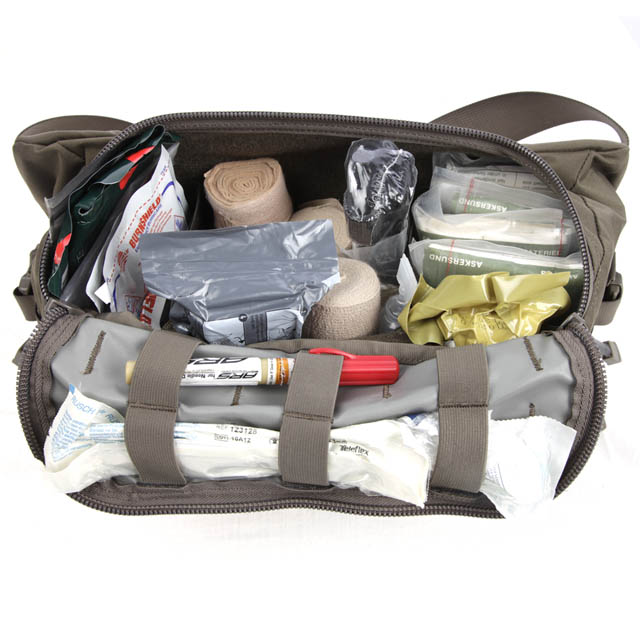


SNIGEL INNOVATIONS
Ergonomic heavy-load backpacks
Ergonomically correct back plate with pivoting hip-belt for heavy-load backpacks.
This was the subject of Per Henrik’s thesis for his Masters degree in Industrial Design. It led to the creation of the legendary 120-litre backpack that was eventually ordered by the Swedish Army. The rest is, as they say, history. The ergonomic shape and structure of the back plate and hip belt rely on biometric data collected from several hundred Swedish draftees. We continue to refine this design and our latest iteration is presented in our Heavy Load Backpack platform.






